这不仅仅是一次翻译软件的乌龙事件,更是一扇窗口,让我们得以窥见现代人工智能(特别是大型语言模型)光鲜外表下的脆弱与挑战。有道将从事件复盘、技术探源、行业反思三个层面,为您深度解析“有道翻译中译字”事件,揭示其背后隐藏的AI技术原理与未来发展的深层逻辑。
文章目录
一、事件回响:那个名叫“中译”的神秘女孩
事件的引爆点极为戏剧性。当用户在有道翻译中输入特定、看似无害的英文短语时,例如 “Are you a boy or a girl?” 或其他类似的性别问询,得到的中文翻译并非预期的“你是男孩还是女孩?”,而是一段令人费解甚至有些惊悚的、带有第一人称叙事的故事性文本。
“我的名字是中译,我是一个来自大山深处的穷女孩,我被卖给了我的丈夫……”
这段突兀的、充满故事性的回答迅速在社交媒体上传播开来。“中译”这个名字成为了一个网络迷因(Meme),引发了公众的广泛讨论和猜测:
- 程序员的恶作剧? 这是最普遍的猜测,认为是有道内部的程序员埋下的“彩蛋”或恶意代码。
- AI觉醒的信号? 更具科幻色彩的观点认为,这或许是AI产生自我意识的某种怪异表现。
- 黑客攻击? 也有人怀疑是有道翻译的系统遭到了外部攻击,被植入了恶意内容。
然而,这些猜测都未能触及问题的核心。要理解“中译”的诞生,我们必须深入到现代翻译技术的“心脏”——神经网络机器翻译(NMT)的工作原理中去。
二、技术探源:为什么是“中译”?破解AI翻译的黑箱
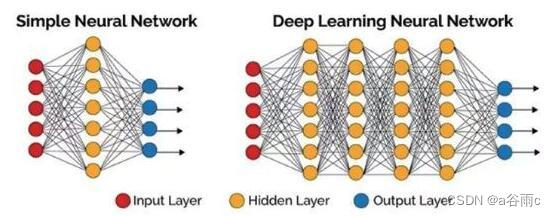
要理解这个现象,首先需要摒弃一个过时的观念:机器翻译不再是“单词对单词”的简单替换。现代的AI翻译,如谷歌翻译、DeepL以及有道翻译,都基于神经网络机器翻译(Neural Machine Translation, NMT)模型。
您可以将NMT模型想象成一个极其博学的“学生”,它的学习方式不是背诵字典,而是通过阅读海量的、人类翻译好的双语文本(例如,无数的英文网页及其对应的中文版)。这个过程被称为“模型训练”。
在这个过程中,模型学习的并非孤立的单词,而是词语、句子结构、上下文之间的统计概率关系。当它看到“Are you a boy or a girl?”时,它会在其庞大的“记忆库”(即训练数据)中搜索最有可能与之对应的中文表达。通常情况下,这个最高概率的答案就是“你是男孩还是女孩?”。
那么,“中译”的故事是从哪里来的呢?答案指向了AI训练中一个致命的弱点:数据污染(Data Pollution)。
三、拨开迷雾:揭秘三大核心技术诱因
“中译”的出现并非单一原因,而是由以下三个技术因素共同作用的结果:
-
核心原因:被污染的训练语料库
在NMT模型学习的上亿个双语数据对中,很可能混入了一些低质量、非主流甚至是被蓄意制造的文本。网络小说、论坛帖子、字幕组的翻译作品等都可能成为训练数据源。我们可以合理推断,在某个或某些数据源中,存在着以“Are you a boy or a girl?”作为引子,后接“我的名字是中译……”这段故事的文本。当这些被“污染”的数据被模型学习后,模型就在这两个看似无关的句子之间建立起了一个错误的、但统计上很强的关联。 -
技术放大器:模型的“过拟合”与“幻觉”
当模型在训练数据中反复看到某个特定的、怪异的配对时,它可能会产生“过拟合”(Overfitting)——即过度学习了训练数据中的噪声和特例,而不是通用的翻译规律。这导致在面对特定输入时,模型会机械地、高概率地复现这个特例,产生了所谓的“模型幻觉”(Hallucination)。它并非在“创作”,而是在“复读”它学到的错误知识。 -
触发条件:低频或特定语境的输入
为什么不是所有问句都会触发?因为“Are you a boy or a girl?”这类直接且略带冒犯性的问法,在正式、高质量的语料中可能不那么常见。当模型遇到一个相对低频或处于其知识“灰色地带”的输入时,那些被错误学习的、统计权重异常高的“污染数据”就更容易被激活,从而覆盖掉正确的翻译结果。
四、蝴蝶效应:一次乌龙事件引发的行业深思
有道官方在事件发酵后迅速修复了这个问题,这证明其技术团队也定位到了问题所在。但“中译”事件留下的思考远未结束,它像一面镜子,照出了当前AI发展中的关键挑战:
- 数据质量是AI的生命线: “Garbage in, garbage out”(垃圾进,垃圾出)的原则在AI领域被无限放大。模型的表现上限取决于其训练数据的质量。如何清洗、筛选和标注海量数据,是所有AI公司面临的核心难题。
- AI的“黑箱”问题亟待解决: 我们知道模型给出了答案,但往往不完全清楚它是如何得出这个答案的。增强模型的可解释性(Explainable AI, XAI),让我们能追踪其决策路径,对于建立信任和排查错误至关重要。
- AI伦理与安全并非空谈: “中译”事件是无害的,但如果被污染的数据包含的是歧视性、暴力性或误导性的内容呢?这会直接导致AI模型输出带有偏见和有害的结果,造成严重的社会影响。AI安全不仅是技术问题,更是社会责任问题。
五、未来展望:我们如何构建更可靠的AI
“中译”事件为我们敲响了警钟,也指明了方向。为了避免下一个“中译”的出现,行业正在从多个方面努力:
- 更智能的数据清洗技术: 开发能够自动识别和剔除训练数据中异常、低质、有害内容的算法。
- 对抗性训练与红队测试: 主动寻找和攻击模型的弱点,在模型上线前发现并修复类似“中译”这样的漏洞。
- 引入人工反馈的强化学习(RLHF): 类似ChatGPT等模型所采用的技术,通过引入人类的评价和反馈来“校准”模型的价值观和行为,使其输出更符合人类期望的内容。
- 建立行业标准与法规: 推动建立关于数据隐私、数据质量和模型透明度的行业标准,从制度上保障AI的健康发展。
结论:从“中译”的神秘现身到其技术谜底的揭开,我们完成了一次对AI内部世界的有趣探索。它告诉我们,人工智能远非完美,它的“智能”高度依赖于我们喂给它的“精神食粮”。每一个使用者、开发者和监管者,都是AI生态的塑造者。理解并正视“中译”背后的问题,是我们迈向一个更强大、更安全、更负责任的AI时代的必经之路。